本周国内最热门的 AI 应用就是 Manus 了。类似的 Agent 应用在国外其实已经不稀奇,但是国内受制于模型能力,暂时落后些。Manus 后端应该还是借助了 Clause 的能力,所以其实仍然只能在海外用。但因为开发团队在武汉,所以给国人好好地普及了一次 Agent 到底能干什么,风风火火地出了一次圈。他们之前开发的 Monica 也是爆款应用,团队的产品能力和营销能力都很强。
我没有亲自试用 Manus,但是根据网络上的一些反馈来看,产品效果好像不及预期。宝玉也写了篇关于 Manus 的博客,里面提到 Manus 把资料整理成 Agent memory 时会有信息损失,再就是通过 OCR 获取屏幕内容也可能会损失信息。链条越长,误差逐步累积,最后结果就很难控制了。有意思的是:Manus 的开发团队名称是【蝴蝶效应】,正好用来解释 Mansu 效果欠佳的原因 😆
紧接着,开源版本 OpenManus 闪电发布,OpenManus 的作者之前就有过大作,就是 MetaGPT。今天我想研究的不是 OpenManus,而是 MetaGPT,因为这个项目我有试用过,效果相当惊艳。这是 MetaGPT 的论文和代码地址:
论文解读
论文的精华部分都在第 3 节:MetaGPT: A Meta-programming Framework
- 遵循标准操作流程的智能体
- 角色专业化
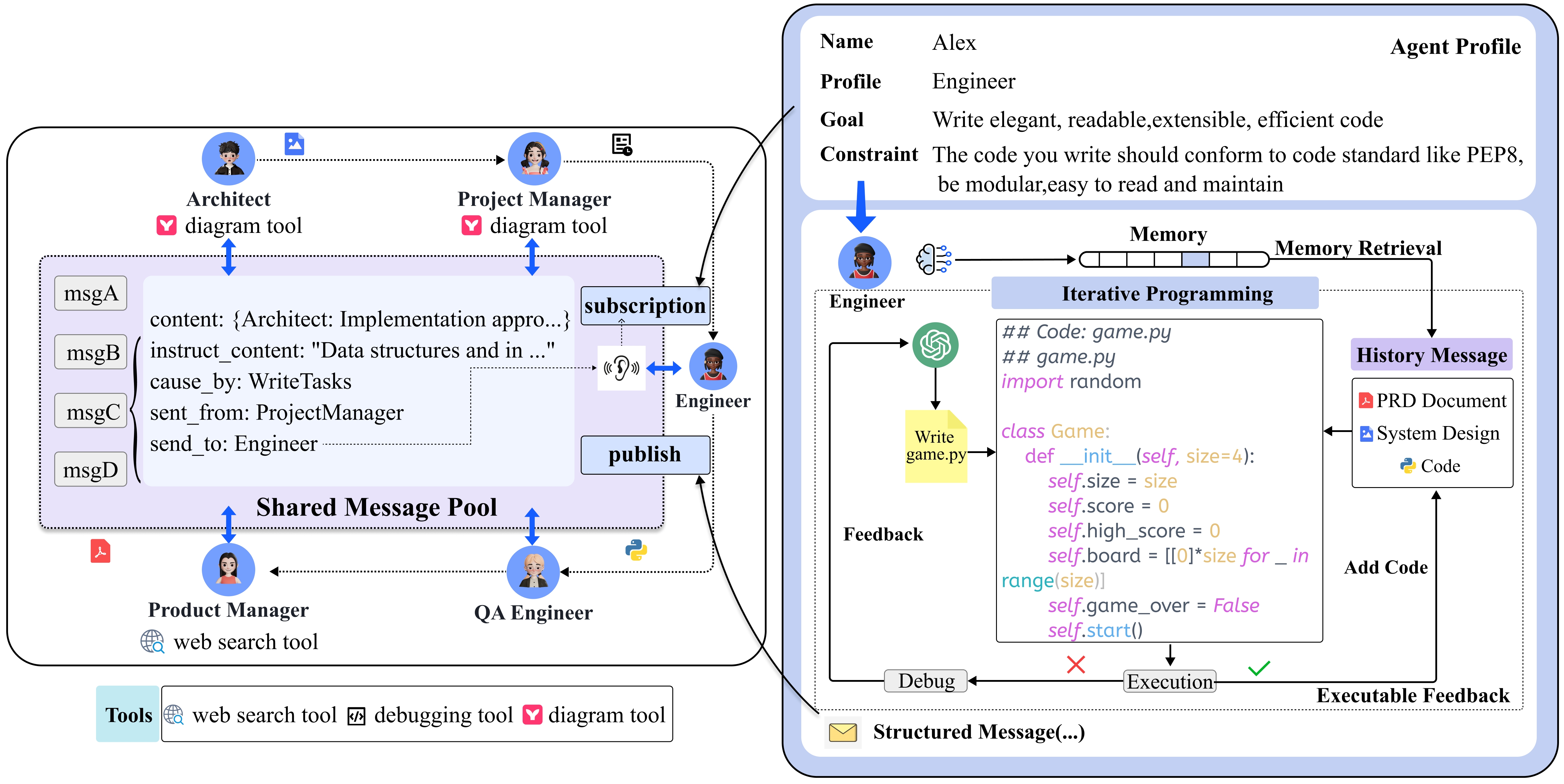
MetaGPT 定义了产品经理、架构师、项目经理、工程师和 QA 工程师等角色。每个角色有明确的职责、技能和目标,如产品经理可使用网络搜索工具进行业务分析,工程师能执行代码。智能体通过监测环境(消息池)中的信息来触发行动。 - 智能体间工作流
依据各角色的职责和技能,MetaGPT 建立了基于软件开发 SOP 的工作流。产品经理根据用户需求生成产品需求文档(PRD),架构师将其转化为系统设计,项目经理负责任务分配,工程师进行代码开发,QA 工程师制定测试用例确保代码质量,最终生成软件解决方案。
- 角色专业化
- 通信协议
- 结构化通信接口
多数现有框架使用无约束自然语言通信,易导致信息失真。MetaGPT 采用结构化通信,为各角色设定通信格式和内容要求,智能体通过文档和图表交流,避免信息模糊和错误。 - 发布 - 订阅机制
为解决信息共享和过载问题,MetaGPT 引入共享消息池和订阅机制。智能体可在消息池发布和获取结构化消息,还能根据角色需求订阅相关信息,提高通信效率。
- 结构化通信接口
- 带可执行反馈的迭代编程
日常编程中调试和优化很关键,但现有方法缺乏自我修正机制。MetaGPT 的工程师智能体生成代码后,会执行代码并编写单元测试用例。若测试不通过,工程师根据结果调试代码,直至测试通过或达到最大重试次数,以此提高代码质量。
代码要点解析
这里先讨论几个要点,完整的架构文档附在文章末尾。
消息订阅机制
论文里的架构图已经说明了,所有角色共享一个消息池。那么每个角色是怎么决定自己要处理哪些消息的呢?
注意 class Message 里这两个字段:
cause_by:角色会订阅自己感兴趣的动作类型,如果消息是由自己感兴趣的动作触发的,那么这个角色就会处理该消息。send_to:如果消息是指定发给某个角色的,那么角色也会处理该消息。
角色记忆
Message 就是基本的记忆单元,记忆就是 Message 的集合。
RoleContext 负责管理角色的记忆,包含 memory 和 working_memory 字段,它们的区别如下:
| 特性 | 主记忆 (memory) | 工作记忆 (working_memory) |
|---|---|---|
| 持久性 | 长期保存,不会主动清除 | 短期使用,任务完成后通常会清除 |
| 作用范围 | 整个对话历史或项目生命周期 | 单个任务执行过程 |
| 内容完整性 | 存储所有相关消息 | 只存储当前任务相关信息 |
| 主要用途 | 消息观察、历史追溯、上下文保持 | 任务规划、思考过程、临时工作区 |
| 清除时机 | 一般不主动清除 | 任务完成后通常会清除 |
| 访问模式 | 通过 memory.get() 获取完整历史 | 通常只关注最近添加的内容 |
在 Plan-and-Act 模式中,working_memory 主要用于:
- 存储计划的各个阶段
- 记录任务执行的中间结果
- 支持任务复审和确认过程
- 任务完成后进行清理,开始新的任务
在 ReAct 模式中,working_memory 主要用于:
- 存储思考过程
- 保存对当前情况的分析
- 支持决策过程
- 通常保持更小的容量,聚焦于当前反应
BrainMemory
BrainMemory 是 MetaGPT 中一种专门为长期对话和智能交互设计的高级记忆系统,主要用于存储、管理和优化对话历史,具有自动内存压缩和智能知识管理的功能。用户与 MetaGPT 交互的所有过程都记录在 BrainMemory 里。所以它与角色记忆 Memory 相比,提供了更多针对长对话场景的高级功能:
- 自动摘要能力:能够自动压缩和摘要长对话历史
- 语义理解功能:能判断文本相关性和上下文重写
- 缓存支持:集成 Redis 缓存支持
- 知识分离:将对话历史与知识分离存储
整体架构分析:
最后,我借助了 Claude 3.7 来帮助解读 MetaGPT 的代码库,基于 commit df9bc18。
核心组件
1. 角色系统 (Roles)
MetaGPT 的核心是基于角色的多智能体系统,主要组件包括:
- Role 类:所有角色的基类,定义在
roles/role.py中。每个角色都有自己的名称、描述、目标和约束条件。- 专业角色:如 ProductManager、Architect、Engineer、QAEngineer 等,每个角色都有特定的职责和技能。
- 角色状态管理:角色有状态机制,可以在不同状态间转换,通过
_think、_act、_observe等方法实现角色的思考、行动和观察。- 反应模式:角色支持多种反应模式,如 REACT、BY_ORDER、PLAN_AND_ACT,控制角色如何处理信息和执行任务。
2. 行动系统 (Actions)
角色通过执行行动来完成任务:
- Action 类:所有行动的基类,定义在
actions/action.py中。- 专业行动:如 WritePRD、WriteCode、WriteTest 等,对应软件开发流程中的不同阶段。
- ActionNode:行动节点,用于构建行动图,支持复杂的行动序列。
- 行动输出:行动执行后产生 ActionOutput,可以被其他角色观察和处理。
3. 环境系统 (Environment)
环境是角色交互的场所:
- Environment 类:基本环境类,管理角色之间的消息传递和交互。
- ExtEnv 类:外部环境接口,用于集成实际的游戏或应用环境。
- 环境 API:通过
mark_as_readable和mark_as_writeable装饰器标记环境的读写 API。- 特定环境:如 AndroidEnv、WerewolfEnv、StanfordTownEnv 等,针对不同应用场景的环境实现。
4. 消息系统 (Messages)
角色之间通过消息进行通信:
- Message 类:基本消息类,包含内容、角色、来源和目标等信息。
- MessageQueue:消息队列,支持异步更新和消息处理。
- 消息路由:通过
cause_by、sent_from、send_to等属性实现消息的定向传递。5. 团队协作 (Team)
团队是角色的集合,用于协同完成复杂任务:
- Team 类:团队类,管理多个角色的协作,定义在
team.py中。- 投资机制:团队有投资和成本管理机制,控制资源使用。
- 项目运行:通过
run_project和start_project方法启动和运行项目。6. 上下文和内存 (Context & Memory)
角色需要上下文和内存来保持状态和历史:
- Context 类:上下文类,存储全局配置和状态。
- Memory 类:内存类,存储角色的历史消息和状态。
- ContextMixin:上下文混入类,提供上下文访问方法。
7. 文档和计划 (Documents & Plans)
项目开发过程中的文档和计划管理:
- Document 类:文档类,表示一个文档,包含路径、文件名和内容。
- Plan 类:计划类,包含目标、上下文和任务列表。
- Task 类:任务类,表示计划中的一个任务,包含指令、代码和结果等。
架构特点
- 多智能体协作:MetaGPT 通过多个专业角色的协作,模拟软件开发团队的工作流程。
- 基于消息的通信:角色之间通过消息进行通信,实现松耦合的交互。
- 状态机驱动:角色和环境都基于状态机模型,通过状态转换驱动行为。
- 可扩展性:通过继承和组合,可以轻松添加新的角色、行动和环境。
- 序列化支持:大部分类都支持序列化和反序列化,便于保存和恢复状态。
- 成本管理:内置成本管理机制,控制 LLM API 调用的成本。
- 模块化设计:代码结构清晰,各模块职责明确,便于维护和扩展。
工作流程
一个典型的 MetaGPT 项目工作流程如下:
- 创建一个团队,添加不同角色(如产品经理、架构师、工程师等)。
- 向团队提供一个想法或需求。
- 产品经理分析需求,创建产品需求文档(PRD)。
- 架构师根据 PRD 设计系统架构。
- 工程师根据架构设计编写代码。
- QA 工程师测试代码并提供反馈。
- 所有角色协作解决问题,直到项目完成。
这种工作流程模拟了真实软件开发团队的协作方式,使 AI 能够更有效地完成复杂的软件开发任务。