Anthropic 区分了工作流和 Agent。工作流是基于预定义代码路径协调LLM和工具的系统;Agent则是让LLM动态引导自身流程和工具使用的系统。
下面重点介绍几种常见的工作流模式:
提示链接(Prompt chaining)
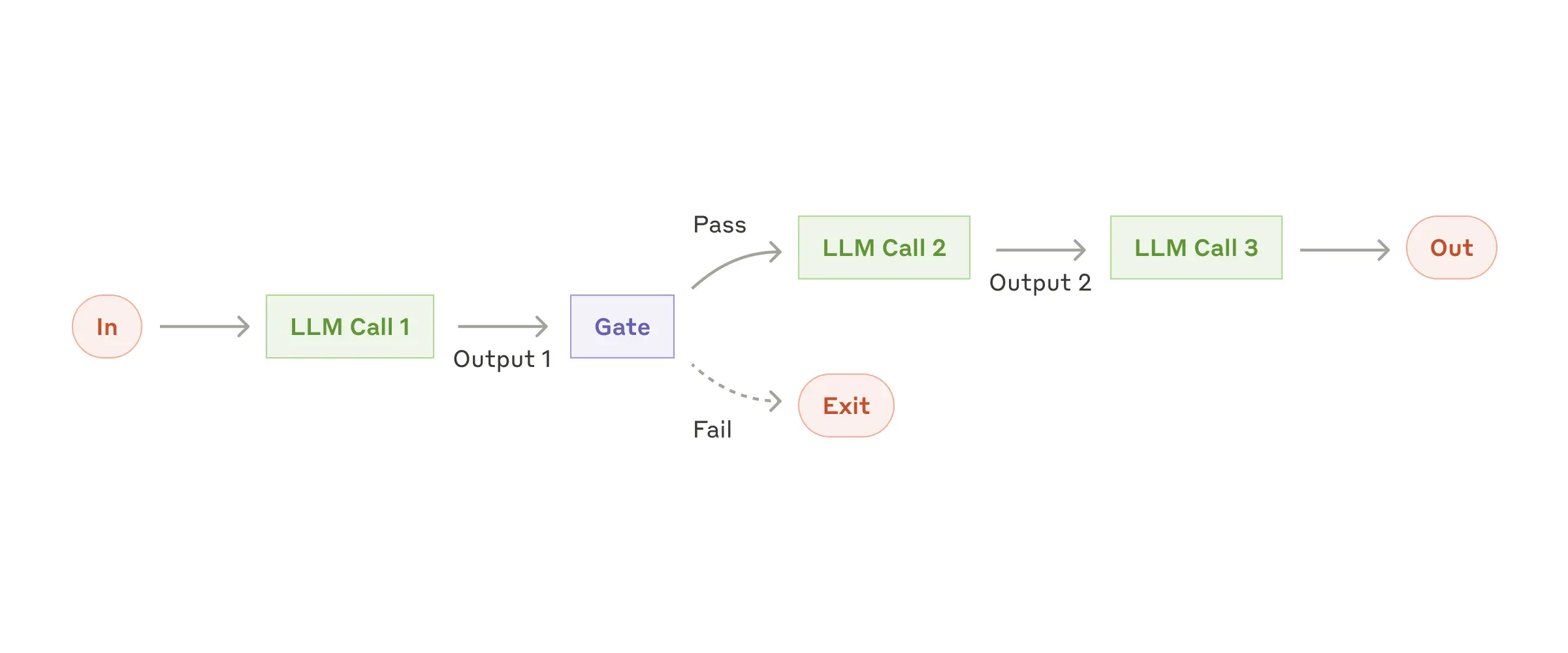
把任务拆解成一连串的步骤,每个LLM调用都基于上一个调用的输出继续处理。还能在中间步骤添加编程检查,确保流程正确推进。这种模式适用于能清晰分解为固定子任务的场景,例如先创作营销文案,再翻译成其他语言;或者先写文档大纲,检查无误后依据大纲完成文档撰写。其目的是通过将复杂任务拆分为简单子任务,以一定的延迟换取更高的准确性。
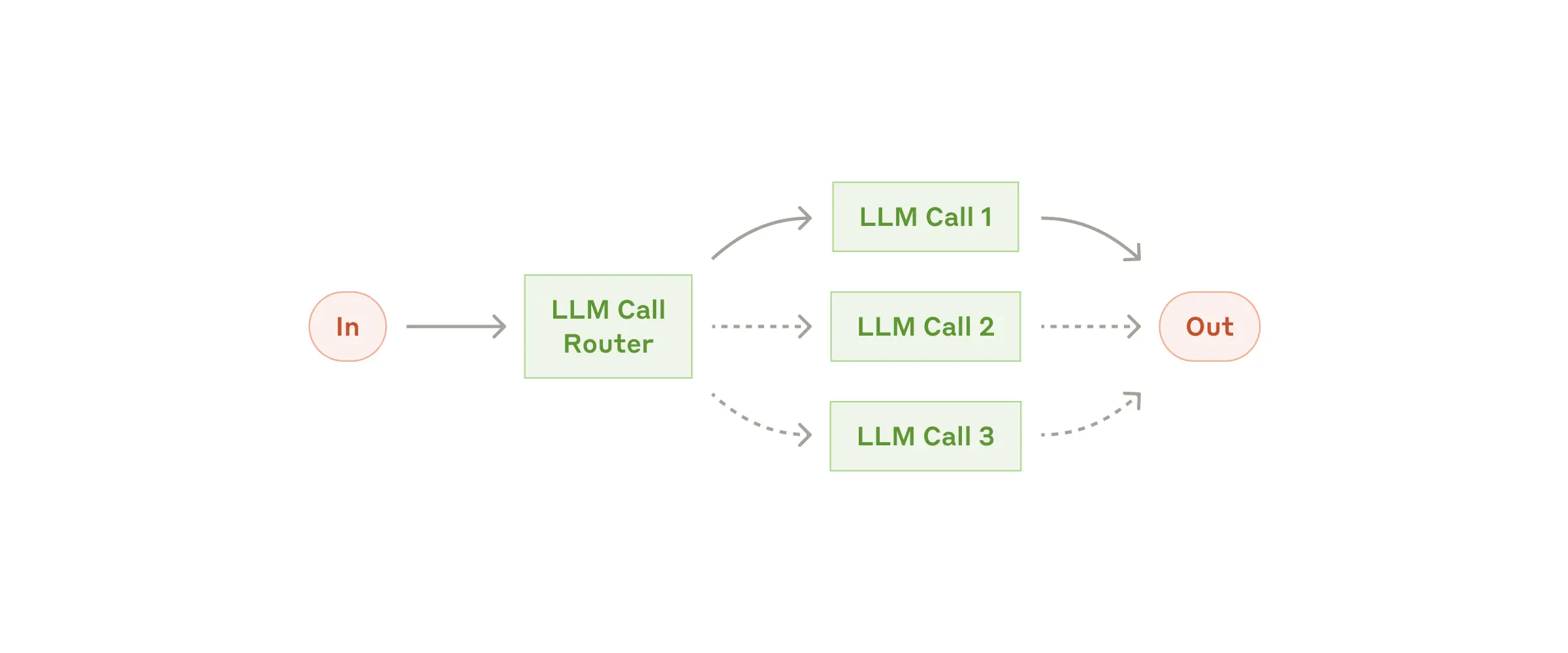
路由(Routing)
对输入内容进行分类,然后将其引导至专门的后续任务。这样可以分开处理不同类型的任务,构建更有针对性的提示。比如在客户服务场景中,将不同类型的咨询(像一般问题、退款申请、技术支持等)分配到不同的处理流程;或者根据问题的难易程度,把简单常见问题交给小型模型处理,复杂罕见问题交给更强大的模型,从而优化成本和处理速度。
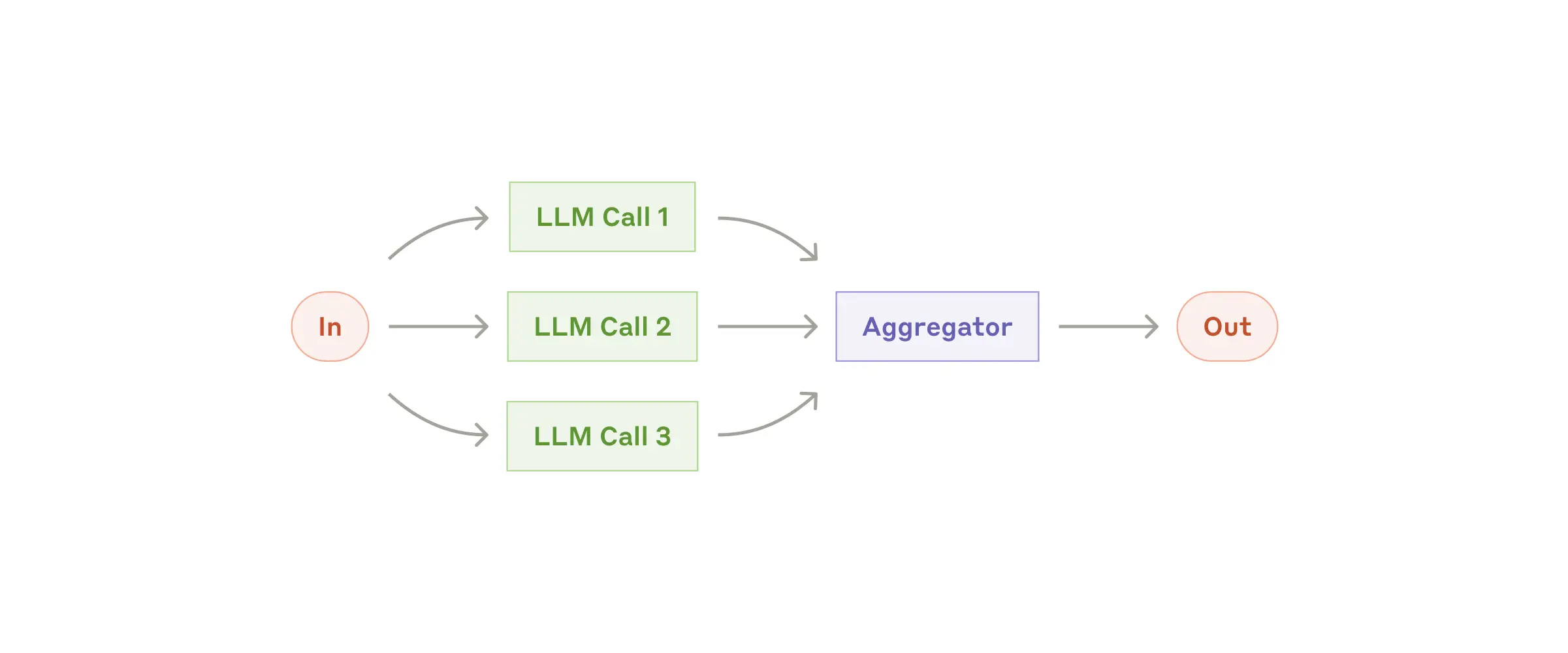
并行化(Parallelization)
LLMs可以同时处理任务,然后将输出结果进行汇总。这种模式有两种主要变体:一是切片,即将任务拆分成多个独立的子任务并行处理,比如在实现防护栏功能时,一个模型实例处理用户查询,另一个负责检查内容是否合规;二是投票,即多次执行同一任务获取不同输出,例如在审查代码漏洞时,用多个不同的提示对代码进行检查和标记。
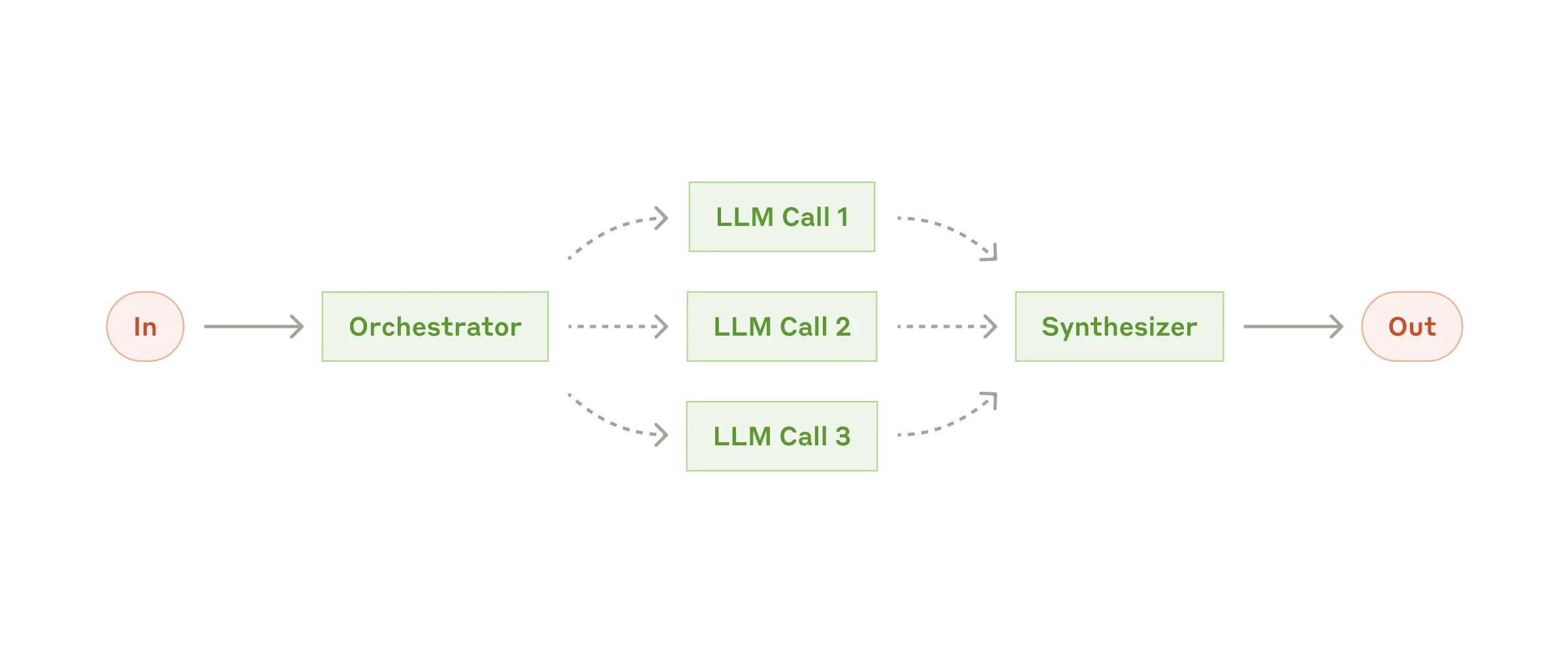
协调器 - 工作器(Orchestrator-workers)
由一个中央LLM负责动态分解任务,把这些子任务分配给多个工作LLM执行,最后再整合它们的结果。这种模式适合那些无法预先确定子任务的复杂任务,例如编码产品需要对多个文件进行复杂修改,或者搜索任务需要从多个来源收集和分析信息。
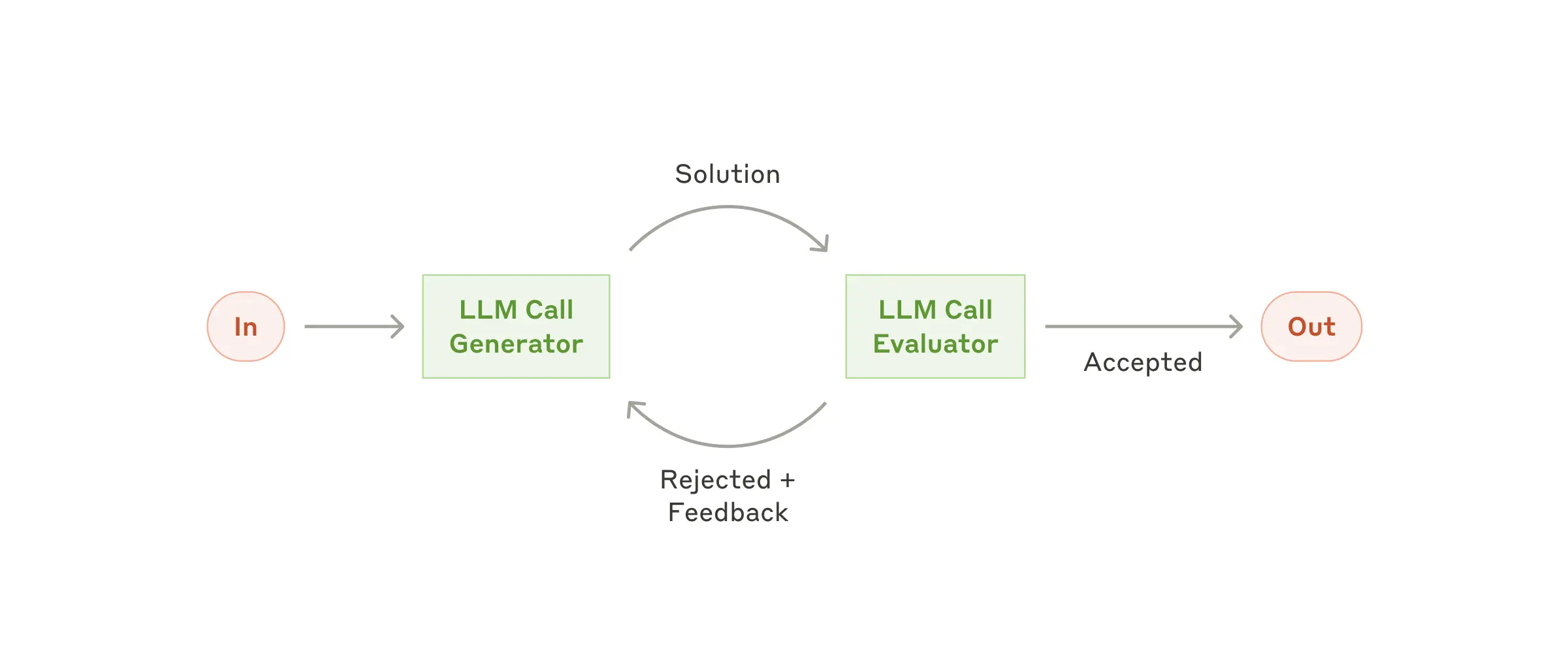
评估器 - 优化器(Evaluator-optimizer)
在这个模式里,一个LLM生成响应,另一个LLM对其进行评估并给出反馈,通过不断循环来优化结果。当有明确的评估标准,且迭代优化能带来明显效果时,这种模式就非常适用。比如在文学翻译中,翻译LLM可能一开始无法捕捉到所有细微之处,评估LLM可以给出有用的修改意见;还有复杂搜索任务,需要经过多轮搜索和分析来获取全面信息,评估器可以判断是否需要进一步搜索。